HADOOP
Hadoop is an open-source software framework for storing data and running applications on clusters of commodity hardware. It provides massive storage for any kind of data, enormous processing power and the ability to handle virtually limitless concurrent tasks or jobs.
BENEFITS OF HADOOP
Computing power. Its distributed computing model quickly processes big data. The more computing nodes you use, the more processing power you have.
Flexibility. Unlike traditional relational databases, you don’t have to preprocess data before storing it. You can store as much data as you want and decide how to use it later. That includes unstructured data like text, images and videos.
Fault tolerance. Data and application processing are protected against hardware failure. If a node goes down, jobs are automatically redirected to other nodes to make sure the distributed computing does not fail. And it automatically stores multiple copies of all data.
Low cost. The open-source framework is free and uses commodity hardware to store large quantities of data.
Scalability. You can easily grow your system simply by adding more nodes. Little administration is required
COMPONENTS COMPRISING HADOOP
Currently, four core modules are included in the basic framework from the Apache Foundation:
Hadoop Common – the libraries and utilities used by other Hadoop modules.
Hadoop Distributed File System (HDFS) – the Java-based scalable system that stores data across multiple machines without prior organization.
MapReduce – a software programming model for processing large sets of data in parallel.
YARN – resource management framework for scheduling and handling resource requests from distributed applications. (YARN is an acronym for Yet Another Resource Negotiator.)
Other software components that can run on top of or alongside Hadoop and have achieved top-level Apache project status include:
Pig – a platform for manipulating data stored in HDFS that includes a compiler for MapReduce programs and a high-level language called Pig Latin. It provides a way to perform data extractions, transformations and loading, and basic analysis without having to write MapReduce programs.
Hive – a data warehousing and SQL-like query language that presents data in the form of tables. Hive programming is similar to database programming. (It was initially developed by Facebook.)
HBase – a nonrelational, distributed database that runs on top of Hadoop. HBase tables can serve as input and output for MapReduce jobs.
HCatalog – a table and storage management layer that helps users share and access data.
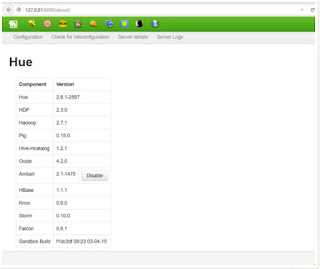
Ambari – a web interface for managing, configuring and testing Hadoop services and components.
Cassandra – A distributed database system.
Chukwa – a data collection system for monitoring large distributed systems.
Flume – software that collects, aggregates and moves large amounts of streaming data into HDFS.
Oozie – a Hadoop job scheduler.
Sqoop – a connection and transfer mechanism that moves data between Hadoop and relational databases.
Spark – an open-source cluster computing framework with in-memory analytics.
Solr – an scalable search tool that includes indexing, reliability, central configuration, failover and recovery.
Zookeeper – an application that coordinates distributed processes.
In addition, there are commercial distributions of Hadoop, including Cloudera, Hortonworks and MapR. With distributions from software vendors, you pay for their version of the framework and receive additional software components, tools, training, documentation and other services.
EXECUTING THE FIRST PROGRAM IN HADOOP
Objective:
We have to execute java coded MapReduce task of three large text files and count the frequency of words appeared in those text files using Hadoop under Hortonworks Data Platform installed on Oracle virtual box.
Framework:
First install the Oracle virtual box and then install hadoop in the virtual box and the installation will take some time.In the mean time have a COFFEE BREAK!!!!
After the installation whenever you want to do something using hortonworks hadoop you need to click on start button in the virtual box which will take some time and give you the screen as below after the completion of installation

After installation process and obtaining the screen as above your system will become very slow don't panic because hadoop requires so much of RAM so I request you to have atleast 6-8 GB of RAM to run hadoop,if you cannot afford buying a system but hungry to learn BIG DATA check out the AWS service which comes with a certain trail period
Copy paste that URL in your web Browser which opens a window and go to the advanced settings and start the hortonworks
It will ask for a username and password
username: root
password: hadoop(but while typing password you will not see the cursor moving don't worry just type hadoop and press enter)
As we have java codes ready we need to create these java files using linux vi command. After editing the document we need to give the following commands to save and exit the editor shell. :w for writing and :q to quit from editor window and come back to shell box.
Please look at the editor window opened in my shell using 127.0.0.1:4200

Below screen is where I edited my SumReducer.java, WordMapper.java and WordCount.java files.

Once your java files are ready for execution we need to create one new folder to save our class files which we are going to compile from java codes.
After creating a folder for class files. We have to execute the following code from shell.
javac -classpath /usr/hdp/2.3.0.0-2557/hadoop/hadoop-common-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/hadoop-mapreduce-client-core-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/commons-cli-1.2.jar -d WC-classes WordMapper.java
#-----
javac -classpath /usr/hdp/2.3.0.0-2557/hadoop/hadoop-common-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/hadoop-mapreduce-client-core-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/commons-cli-1.2.jar -d WC-classes SumReducer.java
#-----
javac -classpath /usr/hdp/2.3.0.0-2557/hadoop/hadoop-common-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/hadoop-mapreduce-client-core-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/commons-cli-1.2.jar:WCclasses -d WC-classes WordCount.java
#----
By using the code above we will be able to create class files of SumReducer, WordMapper & WordCount
What these programs essentially does is : we are having three large text files with lot of words. We are going to reduce this humongous task using reducer and mapper program
As we now have class files of SumReducer, WordMapper and WordCount we should create jar file using the following code.
<code> jar -cvf WordCount.jar -C WCclasses/ .</code>
Next step is to create folder in hdfs file system using the following commands.
<code>hdfs -mkdir user/ru1/wc-input</code>
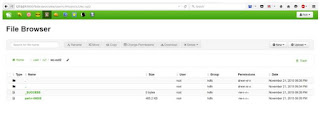
After creating this folder we have to upload files using hue file browser using 127.0.0.1:8000 in our web browser.
After uploading files through file browser. It looks as follows.
Now its time to execute hadoop jar file. Let’s use the following code for doing the same.
hadoop jar WordCount.jar WordCount /user/ru1/wc-input /user/ru1/wc-out





Hadoop is an open-source software framework for storing data and running applications on clusters of commodity hardware. It provides massive storage for any kind of data, enormous processing power and the ability to handle virtually limitless concurrent tasks or jobs.
BENEFITS OF HADOOP
Computing power. Its distributed computing model quickly processes big data. The more computing nodes you use, the more processing power you have.
Flexibility. Unlike traditional relational databases, you don’t have to preprocess data before storing it. You can store as much data as you want and decide how to use it later. That includes unstructured data like text, images and videos.
Fault tolerance. Data and application processing are protected against hardware failure. If a node goes down, jobs are automatically redirected to other nodes to make sure the distributed computing does not fail. And it automatically stores multiple copies of all data.
Low cost. The open-source framework is free and uses commodity hardware to store large quantities of data.
Scalability. You can easily grow your system simply by adding more nodes. Little administration is required
COMPONENTS COMPRISING HADOOP
Currently, four core modules are included in the basic framework from the Apache Foundation:
Hadoop Common – the libraries and utilities used by other Hadoop modules.
Hadoop Distributed File System (HDFS) – the Java-based scalable system that stores data across multiple machines without prior organization.
MapReduce – a software programming model for processing large sets of data in parallel.
YARN – resource management framework for scheduling and handling resource requests from distributed applications. (YARN is an acronym for Yet Another Resource Negotiator.)
Other software components that can run on top of or alongside Hadoop and have achieved top-level Apache project status include:
Pig – a platform for manipulating data stored in HDFS that includes a compiler for MapReduce programs and a high-level language called Pig Latin. It provides a way to perform data extractions, transformations and loading, and basic analysis without having to write MapReduce programs.
Hive – a data warehousing and SQL-like query language that presents data in the form of tables. Hive programming is similar to database programming. (It was initially developed by Facebook.)
HBase – a nonrelational, distributed database that runs on top of Hadoop. HBase tables can serve as input and output for MapReduce jobs.
HCatalog – a table and storage management layer that helps users share and access data.
Ambari – a web interface for managing, configuring and testing Hadoop services and components.
Cassandra – A distributed database system.
Chukwa – a data collection system for monitoring large distributed systems.
Flume – software that collects, aggregates and moves large amounts of streaming data into HDFS.
Oozie – a Hadoop job scheduler.
Sqoop – a connection and transfer mechanism that moves data between Hadoop and relational databases.
Spark – an open-source cluster computing framework with in-memory analytics.
Solr – an scalable search tool that includes indexing, reliability, central configuration, failover and recovery.
Zookeeper – an application that coordinates distributed processes.
In addition, there are commercial distributions of Hadoop, including Cloudera, Hortonworks and MapR. With distributions from software vendors, you pay for their version of the framework and receive additional software components, tools, training, documentation and other services.
EXECUTING THE FIRST PROGRAM IN HADOOP
Objective:
We have to execute java coded MapReduce task of three large text files and count the frequency of words appeared in those text files using Hadoop under Hortonworks Data Platform installed on Oracle virtual box.
Framework:
First install the Oracle virtual box and then install hadoop in the virtual box and the installation will take some time.In the mean time have a COFFEE BREAK!!!!
After the installation whenever you want to do something using hortonworks hadoop you need to click on start button in the virtual box which will take some time and give you the screen as below after the completion of installation

After installation process and obtaining the screen as above your system will become very slow don't panic because hadoop requires so much of RAM so I request you to have atleast 6-8 GB of RAM to run hadoop,if you cannot afford buying a system but hungry to learn BIG DATA check out the AWS service which comes with a certain trail period
Copy paste that URL in your web Browser which opens a window and go to the advanced settings and start the hortonworks
It will ask for a username and password
username: root
password: hadoop(but while typing password you will not see the cursor moving don't worry just type hadoop and press enter)
As we have java codes ready we need to create these java files using linux vi command. After editing the document we need to give the following commands to save and exit the editor shell. :w for writing and :q to quit from editor window and come back to shell box.
Please look at the editor window opened in my shell using 127.0.0.1:4200

Below screen is where I edited my SumReducer.java, WordMapper.java and WordCount.java files.

Once your java files are ready for execution we need to create one new folder to save our class files which we are going to compile from java codes.
After creating a folder for class files. We have to execute the following code from shell.
javac -classpath /usr/hdp/2.3.0.0-2557/hadoop/hadoop-common-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/hadoop-mapreduce-client-core-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/commons-cli-1.2.jar -d WC-classes WordMapper.java
#-----
javac -classpath /usr/hdp/2.3.0.0-2557/hadoop/hadoop-common-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/hadoop-mapreduce-client-core-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/commons-cli-1.2.jar -d WC-classes SumReducer.java
#-----
javac -classpath /usr/hdp/2.3.0.0-2557/hadoop/hadoop-common-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/hadoop-mapreduce-client-core-2.7.1.2.3.0.0-2557.jar:/usr/hdp/2.3.0.0-2557/hadoop-mapreduce/commons-cli-1.2.jar:WCclasses -d WC-classes WordCount.java
#----
By using the code above we will be able to create class files of SumReducer, WordMapper & WordCount
What these programs essentially does is : we are having three large text files with lot of words. We are going to reduce this humongous task using reducer and mapper program
As we now have class files of SumReducer, WordMapper and WordCount we should create jar file using the following code.
<code> jar -cvf WordCount.jar -C WCclasses/ .</code>
Next step is to create folder in hdfs file system using the following commands.
<code>hdfs -mkdir user/ru1/wc-input</code>
After creating this folder we have to upload files using hue file browser using 127.0.0.1:8000 in our web browser.
After uploading files through file browser. It looks as follows.

Now its time to execute hadoop jar file. Let’s use the following code for doing the same.
hadoop jar WordCount.jar WordCount /user/ru1/wc-input /user/ru1/wc-out

After it is executed without any errors we need track the status of application in the all applications page using 127.0.0.1:8088
The screen looks as follows

In this step we should see succeeded in the respective application. After confirming the success status we should open hue file browser where we will see a new folder created called wc-out2 (which we have given in shell command prompt).

In this folder there will be two files called success and part-r-0000. The part-r-0000 is where we can check the output of the program and how many words are there and what is the frequency of each word occurred.



Thank You !
seen
ReplyDeletegood explaination about hadoop and map reduce ,
ReplyDeletei found more resources where you can find tested source code of map reduce programs
refere this
top 10 map reduce program sources code
top 10 Read Write fs program using java api
top 30 hadoop shell commands
Thank you for your guide to with upgrade information about Hadoop
ReplyDeleteHadoop Admin Online Course
Nice blog,keep sharing more posts with us.
ReplyDeleteThank you...
hadoop admin online training
The unique angle you've taken in addressing this subject is refreshing and keeps readers intrigued throughout. auto clicker prove invaluable when dealing with repetitive tasks, such as filling out forms, clicking through multiple screens, or performing monotonous actions in games or applications.
ReplyDelete